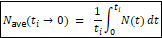Dennis McCarthy recently put up a post offering a detailed critique of the Amazon-banned Amazon bestseller Probability Zero. We don’t know that it was publishing Probability Zero and the effectiveness of the book that inspired some evolutionary enthusiast in the KDP department to ban Castalia’s account, but we can be very confident that it wasn’t because Castalia submitted my own Japanese translation of my own book for publication without having the right to do so, as we were informed.
In any event, McCarthy’s critique is the first substantive one we’ve seen and it’s a more competent attempt to engage with the mathematical arguments in Probability Zero than those from Redditors opining in ignorance, but his critique immediately fails for multiple reasons that demonstrate the significant difference between biological intuition and mathematical rigor. For some reason, McCarthy elects to focus on the Darwillion, my probability calculation about the likelihood of evolution by natural selection instead of MITTENS itself, but that’s fine. Either way, there was no chance he was going to even scratch the paint on the proven fact of the mathematical impossibility of natural selection.
“What Vox Day calculated—(1/20,000)^20,000,000—are the odds that a particular group or a pre-specified list of 20 million mutations (or 20 million mutations in a row) would all become fixed. In other words, his calculation would only be accurate if the human race experienced only 20 million mutations in total over the last 9 million years—and every one of them then became fixed… Using Vox Day’s numbers, in a population of 10,000 humans, we would expect, on average, 50,000 new mutations per year. And over the course of 9 million years, this means we would expect: 50,000 × 9 million = 450 billion new mutations altogether. So out of 450 billion mutations, how many mutations may we expect to achieve fixation? Well, as Vox Day noted, each mutation has a probability of 1/20,000 in becoming fixed. 450 billion × 1/20,000 = 22.5 million fixed mutations.”
This is a category error. What McCarthy has done here is abandon Darwin, abandon natural selection, and retreated to an aberrant form of neutral theory that he’s implementing without even realizing that he has done so. He’s cargo-culting the structure of Kimura’s core equation that underlies neutral theory without understanding what the terms mean or where they come from. Because my numbers weren’t arbitrary, they are straight out of Kimura’s fixation model.
So he took my number for mutations arising, which depends on effective population (Nₑ), multiplied it by the fixation probability (which depends on 1/Nₑ), and got the textbook neutral theory answer because the Nₑ terms cancel each other out. He wrote it as “mutations × probability” because he was reverse-engineering an argument to match the observed 20 million, not applying the theory directly. It’s rather like someone proving F=ma by measuring force and acceleration separately, then multiplying them together and thinking they’ve discovered mass. It’s technically correct, yes, but also completely misses the point.
The next thing to point out is that not only is what he’s cited incorrect and irrelevant, it isn’t even a defense of evolution through natural selection. McCarthy’s rebuttal has nothing to do with Darwin, nothing to do with adaptation, nothing to do with fitness, nothing to do with selection pressure, nothing to do with speciation, and nothing to do with all of the biogeography that McCarthy later lovingly details. Neutral theory, or genetic drift, if you prefer, is what happens automatically over time, and it is appealed to by biologists as a retreat from Neo-Darwinism to try to explain the existence of these huge genetic caps for which they know natural selection and sexual selection cannot possibly account.
Even the great defender of orthodox Darwinism, Richard Dawkins, has retreated from TENS. It’s now “the Theorum of Evolution by (probably) Natural Selection, Sexual Selection, Biased Mutation, Genetic Drift, and Gene Flow.” Or, as I prefer to call it, TE(p)NSSSBMGDAGF.
This is exactly what I mean when I talk about evolutionary epicycles.
And in the interest of perfect clarity, note this: Dennis McCarthy’s critique of Probability Zero is not, in any way, a defense of evolution by natural selection. Nor can it be cited as a defense of speciation or Darwinism at all, because neutral theory has as about as much to do with Darwin as the Book of Genesis. But don’t take my word for it, listen to the scientist himself:
“In sharp contrast to the Darwinian theory of evolution by natural selection, the neutral theory claims that the overwhelming majority of evolutionary changes at the molecular level are caused by random fixation (due to random sampling drift in finite populations) of selectively neutral (i.e., selectively equivalent) mutants under continued inputs of mutations.”
—Kimura, M. “The neutral theory of molecular evolution: a review of recent evidence.” Japanese Journal of Genetics
But that’s not the only problem with the critique. McCarthy’s calculation is correct for the number of mutations that enter the population. That tells you precisely nothing about whether those mutations can actually complete fixation across the entire reproducing population within the available time. He has confused mutation with fixation, as do the vast majority of biologists who attempt to address these mathematical challenges. I don’t know why they find it so difficult, as presumably these scientists are perfectly capable of communicating that they only want one burrito from Taco Bell, and not 8 billion, with their order.
McCarthy’s calculation implicitly assumes that fixation is instantaneous. He’s assuming that when a mutation appears, it has a 1/20,000 chance of succeeding, and if it succeeds, it immediately becomes fixed in 100% of the population. But this is not true. Fixation is a process that takes time. Quite often, a lot of time. Because if McCarthy had understood that he was utilizing Kimura’s fixation model in his critique, then he would known to have taken into account that the expected time to fixation of a neutral mutation is approximately 4Nₑ generations, which is around 40,000 generations for an effective population size of 10,000.
In other words, he actually INCREASED the size of the Darwillion by a factor of 25. I was using a time-to-fixation number of 1,600. He’s proposing that increasing that 1,600 to 40,000 is somehow going to reduce the improbability, which obviously is not the case. The problem is due to the fact that all fixations must propagate through actual physical reproduction. Every individual carrying the fixing allele must reproduce, their offspring must survive, those offspring must reproduce, and so on—generation after generation, for tens of thousands of generations—until the mutation reaches 100% frequency throughout the entire reproducing population.
Here’s the part that McCarthy omitted: can those 22 million mutations actually complete and become fixated through this reproductive process in 450,000 generations once they appear? Of course they can’t! Both reasons are related to the limits on natural selection and are explained in great detail in the book:
- The Reproductive Ceiling: Selection operates through differential reproduction. For mutations to fix faster than neutral drift, carriers must outreproduce non-carriers. But humans can only produce a limited number of offspring per generation. A woman might have 10 children in a lifetime; a man might sire 100 under exceptional circumstances. This places a hard ceiling on how much selection can operate simultaneously across the genome.
- The Bernoulli Barrier: Even if we invoke parallel fixation (many mutations fixing simultaneously), the Law of Large Numbers creates a devastating problem. As the number of simultaneously segregating beneficial loci increases, the variance in individual fitness decreases relative to the mean. Selection requires variance to operate; parallel fixation destroys the variance it needs. This constraint is hard, but purely mathematical, arising from probability theory rather than biology.
McCarthy’s second objection concerns the 2009 Nature study on E. coli:
“Unfortunately, this analysis is flawed from the jump: E. coli does not exhibit the highest mutation rate per generation; in fact, it has one of the lowest—orders of magnitude lower than humans when measured on a per-genome, per-generation basis.”
McCarthy is correct that humans have a higher per-genome mutation rate than E. coli—roughly 60-100 de novo mutations per human generation versus roughly one mutation per 1000-2400 bacterial divisions. But this observation is irrelevant. Once again, he’s confusing mutation with fixation.
I didn’t cite the E. coli study for its mutation rate but for its fixation rate: 25 mutations fixed in 40,000 generations, yielding an average of 1,600 generations per fixed mutation. These 25 mutations were not fixed sequentially—they fixed in parallel. So the 1,600-generation rate already takes parallel fixation into account.
Now, McCarthy is operating under the frame of Kimura, and he assumes that since mutations = fixations, the fact that humans mutate faster than bacteria means that they fixate faster. Except they don’t. No one has ever observed any human or even mammalian fixation faster than 1,600 generations. Even if we very generously extrapolate from the existing CCR5-delta32 mutation that underwent the most intense selection pressure ever observed, the fastest we could get, in theory, is 2,278 generations, and even that fixation will never happen because the absence of the Black Death means there is no longer any selection pressure or fitness advantage being granted by that specific mutation.
Which means that in the event neutral drift carries CCR5-delta32 the rest of the way to fixation, it will require another 37,800 generations in the event that it happens to hit on its 10 percent chance of completing fixation from its current percentage of the global population.
In short, the fact that E. coli mutate slower doesn’t change the fact that humans don’t fixate faster.
The rest of the critique is irrelevant and incorrect. I’ll address two more of his points:
Finally, there is no brake—no invisible wall—that arbitrarily halts adaptation after some prescribed amount of change. Small variations accumulate without limit. Generation after generation, those increments compound, and what begin as modest differences become profound transformations. When populations of the same species are separated by an earthly barrier—a mountain, a sea, a desert—they diverge: first into distinct varieties or subspecies, and eventually into separate species. And precisely what this process predicts is exactly what we find. Everywhere, without exception.
This is a retreat to the innumeracy of the biologist. There is absolutely a hard limit, a very visible flesh-and-blood wall, that prevents adaptation and renders natural selection almost irrelevant as a proposed mechanism for evolution. That is the reproductive barrier, which is far stronger and far more significant than the earthly barriers to which McCarthy appeals.
I don’t know why this is so hard for evolutionary enthusiasts to grasp: we actually know what the genetic distance between two different species are. We know the amount of time that it took to create that genetic gap. And there are not enough generations, not enough births, not enough reproductions, to account for ANY of the observed genetic gaps in the available amount of time.
Imagine a traveler made the same appeal in order to support his claim about his journey.
There is no brake—no invisible wall—that arbitrarily halts movement after some prescribed amount of steps. Small steps accumulate without limit. Block after block, those increments compound, and what begin as modest differences become profound transformations. When man is separated from his earthly objective—a city on a distant shore—he begins to walk, first across county lines, and then across states, over mountains, through forests, and even across deserts. And precisely what this process predicts is exactly what we find. Everywhere, without exception. That is why you must believe that I walked from New York City to Los Angeles in five minutes.
Dennis McCarthy is a very good writer. I envy the lyricism of his literary style. Hell, even Richard Dawkins, who is a lovely and engaging writer, might well envy him. But what he entirely fails to grasp is that Probability Zero isn’t an end run, as he calls it. It is an undermining, a complete demolition of the entire building.
The book is first and foremost what I like to call an end-around. It does not present a systematic attack on the facts just presented—or, for that matter, any of the vast body of empirical evidence that confirms evolution. It sidesteps entirely the biogeographical patterns that trace a continuous, unbroken organic thread that runs through all regions of the world, with the most closely related species living near each other and organic differences accruing with distance; the nested hierarchies revealed by comparative anatomy and genetics; the fossil record’s ordered succession of transitional forms (see pic); directly observed evolution in laboratories and natural populations; the frequency of certain beneficial traits (and their associated genes) in human populations, etc.
He’s absolutely correct to observe that I don’t attack or address any of those things in Probability Zero. I didn’t need to do so. It’s exactly like pointing out how I haven’t admired the arrangement of the furniture on the fifth floor or taken in the lovely view from the twentieth when I planted the explosives in the underground supports and the entire building is lying in smoking rubble. Natural selection never accounted for any of those things to which he appeals. It could not possibly have done so, and neither could genetic drift.
All those things exist, to be sure but they do not exist because of evolution by natural selection. Mr. McCarthy will need to find another mechanism to explain them. Which, of course, is something I pointed out in the book. IGM might be an answer, but perhaps there are other mechanisms, although I will caution the enthusiast that so far, every single one of the various natural possibilities suggested, including viruses, similarly fail to address the relevant reproductive constraints and therefore are not viable.
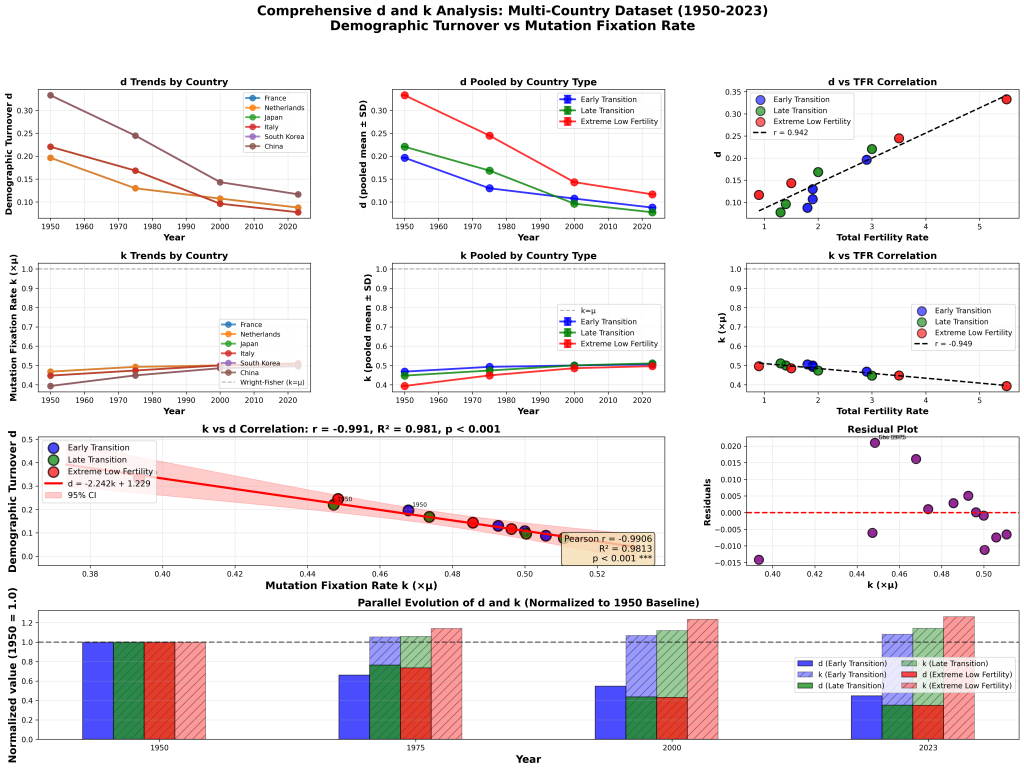
Now, all that being said, I am extremely grateful to Dennis McCarthy for his critique, because the way in which he indirectly invoked the Kimura fixation model inspired me to look directly at its core equation for the first time. Now, I knew that the model was incomplete, which is why I first created a corrective for its failure to account for overlapping generations, the Selective Turnover Coefficient. And I also knew that it was not a constant 10,000 as it is commonly utilized by biologists, because my analysis of the ancient DNA database proved that it varied between 3,300 and 10,000.
But I didn’t know that Kimura’s core equation underlying the fixation model was a burning dumpster fire that is reliant upon on a symbolic amphiboly until looking at it from this different perspective. And the result was the paper “Breaking Neutral Theory: Empirical Falsification of Effective Population-Size Invariance in Kimura’s Fixation Model.” You can read the preprint if you enjoy the deep dives into this sort of thing as I know at least three of you do. Here is the abstract:
Kimura’s neutral theory includes the famous invariance result: the expected rate of neutral substitution equals the mutation rate μ, independent of population size. This result is presented in textbooks as a general discovery about evolution and is routinely applied to species with dramatically varying population histories. It is not generally true. The standard derivation holds exactly only for a stationary Wright-Fisher population with constant effective population size. When population size varies—as it does in virtually every real species—the expected neutral substitution rate depends on the full demographic trajectory and is not equal to μ. We demonstrate this mathematically by showing that the standard derivation uses a single symbol (Ne) for two distinct quantities that are equal only under constant population size. We then show that the direction of the predicted deviation matches observed patterns in three independent mammalian comparisons: forest versus savanna elephants, mouse versus rat, and human versus chimpanzee. Kimura’s invariance is an approximation valid only under demographic stationarity, not a general law. Evolutionary calculations that apply it to species with changing population sizes are unreliable.
Let’s just say neutral theory is no longer a viable retreat for the Neo-Darwinians. The math is real. I wouldn’t go so far as to say that the math is the only reality, but it is definitely the one thing you cannot ever ignore if you want to avoid having all your beautiful theories and assumptions and beliefs destroyed in one fell swoop.
Probability Zero will be in print next week. You can already preorder the print edition at NDM Express. And for an even deeper dive into the evolutionary science, The Frozen Gene will be available in ebook format, although whether it will be on Amazon or not is yet to be determined. And finally, I’ll address the comments from McCarthy’s post in a separate post.
DISCUSS ON SG