Unlike the mainstream science orthodoxy, I don’t feel any need to avoid admitting when I got something fundamentally wrong, fixing the problem, and revising my conclusions. Which, of course, is why I’m working on the new appendices for the second edition of Probability Zero rather than trying to defend, rationalize, and justify the various mistakes I made in the first edition, which were mostly the result of relying upon the consensus numbers produced in 2005 rather than the 2025 update of them.
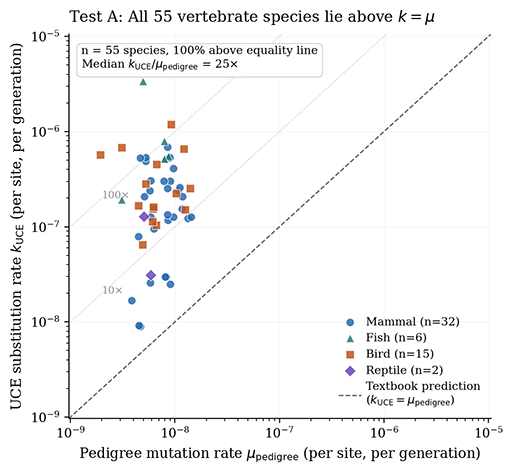
Claude Athos and I are now revising the Kimura’s Calculator paper from last week because our subsequent empirical work has identified a category error in how the selection-cost binding constraint was being used in it. The original paper presents the Calculator as a three-term framework in which the realized substitution rate equals the minimum of three serial constraints: the corrected input flux (Term 1), the polymorphism throughput ceiling (Term 2), and the selection-cost limit (Term 3). For sexual eukaryotes, Term 3 binds at approximately 10⁻¹², two to four orders of magnitude below Terms 1 and 2, which made it the headline result and drove the framework’s most dramatic predictions. The new validation work which uses Bergeron et al. (2023) on pedigree mutation rates and fossil-calibrated substitution rates for 55 vertebrate species exposed a fundamental problem that three-term construction.
The category error is this: Term 3 is derived from Haldane’s cost-of-substitution argument, which bounds the rate at which selection can drive adaptive fixations through a population given finite reproductive capacity. It is a constraint on selectively driven substitutions alone, not on total substitutions. The original Calculator paper treats Term 3 as a bound on total substitution rate and compares it against observed substitution rates from sequence divergence, but observed substitution rates include both neutral fixations (which are the great majority) and adaptive fixations (which are comparatively rare). Comparing Term 3 against total observed k is therefore comparing a bound on adaptive substitutions against a quantity that is mostly comprised of neutral substitutions. The two simply aren’t measuring the same thing. While the math of Term 3 is correct for the quantity to which it actually applies; my error was in interpreting its output as a constraint on total k. Once corrected, Term 3 still limits adaptive substitution rate at ~10⁻¹², but total substitution rate is only governed by Terms 1 and 2, which now falls in the 10⁻⁷ to 10⁻⁸ range that is consistent with the empirically observed rates.
The ramifications for our conclusions are significant but not catastrophic, and the revised picture is in some ways stronger than the original because it survives empirical scrutiny that the original would not. The textbook k = μ identity is still falsified — both directly (pedigree μ and phylogenetic k disagree by a median factor of 25 across 55 vertebrates) and structurally (the polymorphism throughput ceiling is exceeded by textbook μ for 95.4% of 173 animal species). The cancellation step in Kimura’s derivation still fails because N ≠ Nₑ in real populations, as Frankham cataloged thirty years ago. What has to be revised is the magnitude of the resulting recalibrations to molecular-clock divergence dates. The corrected framework predicts factor 10 corrections rather than factor 100,000 corrections, which still places significant divergences in substantially different time ranges than the textbook gives but doesn’t compress the entirety of evolutionary deep time the way the original Term 3 framing implied.
To put this in context, it means that the CHLCA event falls somewhere in the 250 kya to 1.3 Mya range rather than the 6.3 Mya presently assumed. But it cannot be as recent as the lower end of the 68 kya to 330 kya range that had orginally been calculated on the basis of the erroneous calculator.
The result of this retraction and revision is that the central critique of neutral theory survives and is now backed by two methodologically independent empirical tests rather than a theoretical framework with a contested parameter. Kimura’s identity is still wrong, the molecular clock as currently calibrated still overstates divergence times, and the Neo-Darwinian accounting of sequence evolution still rests on a Wright-Fisher idealization that doesn’t describe real populations. The fix is more conceptual than catastrophic and will require properly labeling what each constraint measures, accepting more modest recalibration magnitudes than Term 3 originally suggested, and grounding the falsification more solidly in the empirical evidence rather than theoretical derivation.
We did the best we could with what we had at the time of the original paper; the addition of the empirical data allows us to refine the framework and make the case stronger and more conclusive.